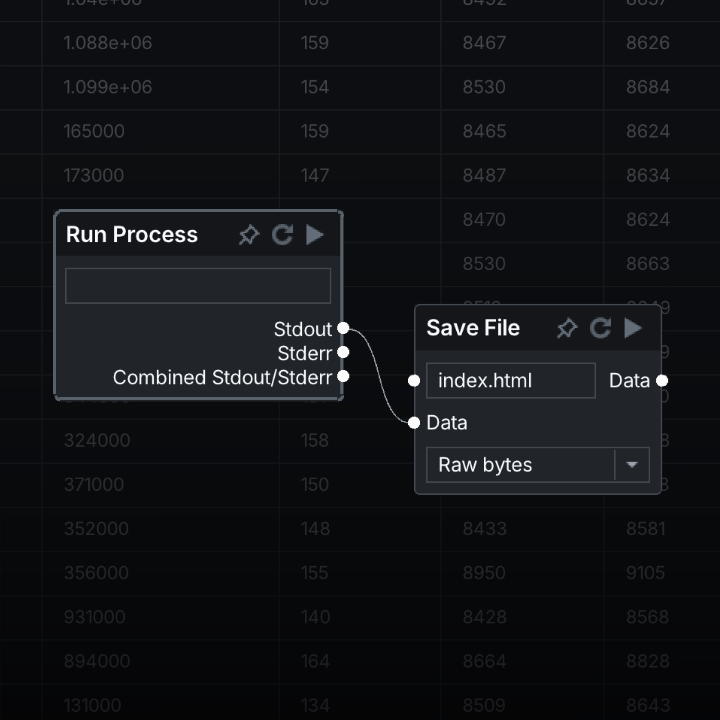
My jam project this year is called Flowshell. It is a visual shell that jettisons the entire concept of the command line.
If you haven't yet, please watch the 10-minute video demo:
https://www.youtube.com/watch?v=VyqxUs1mUng
Tech
Flowshell is written in Go, using Raylib for the platform layer, and Clay for UI layout.
This is a bit of a hodgepodge, but a hodgepodge of components I like. I chose Go because I have experience doing process management in it, and it is overall my most-used language. There are also good Raylib bindings for Go. There are not great Clay bindings for Go, as far as I can tell. The first day of the jam was spent just setting up my own.
By day 3 I was convinced I had made a mistake and should have chosen other tech. In the end, though, I think I made the correct decisions in every way. Making my own Clay bindings was a very tedious up-front investment, but paid of