Noid Enterprise Business Platform
![]()
Background
Originally I intended to write a small programming language on RISCY BUSINESS called Hula. This was not to be a big idea language, just a minimal systems programming language in the space between assembly and C. The name was derived from High-Level Assembler. However, Ryan Fleury began telling me about non-textual programming ideas on IRC and how Allen and others on the handmade network discord were playing around with such ideas (this was before Dion was announced). Ryan's enthusiasm was infectious and I decided that I would make Hula one of these types of systems instead of what I had originally planned... However, RISCY BUSINESS has been on hold, so time has passed by...
Fast forward to the months leading up to the Jam, and I've been active in the Discord community thanks to the IRC-bridge! People have joked before about the community tendency to use the letters [D, I, N, O] (Odin, Ion, Dion...) in naming their programming language projects. Noid is OBVIOUSLY the best possible sequence: It fits the scheme, it has existing associations such as the old Domino's Pizza mascot and slang for paranoia (Death Grips - I've Seen Footage). Furthermore, it happens to be Dion in reverse and my project JUST SO HAPPENS to be a system like Dion... Christoffer Lernö doesn't seem to want the name Noid for C3 so... how could I pass on this glorious naming opportunity?!
Next I'll explain what I've accomplished with my jam entry, but you'll need to be familiar with the terminology I am using first. I wrote up my thoughts on this back in 2020, and I've attached it to this post at the end (see the Programming Languages and Data Systems section). You'll want to give that a read and then continue reading here.
About Noid
Okay, you've read the Programming Languages and Data Systems section? No? Well then what are you doing here? Go read that first (and maybe order some Domino's Pizza while you're at it)!
For the Jam I decided to try my hand at implementing the lowest level layers of Noid (formerly Hula). As you saw mentioned in my old write-up, being able to bootstrap from essentially nothing is an important goal for me, so naturally the lowest level layers need to be very minimal and thus suitable in scope for a jam project.
Because this was a jam, most people (currently) do not have actual RISC-V systems, and my daily-drivers are x86_64 machines as well, I decided to target x86_64 instead of RISC-V for this. If you follow RISCY BUSINESS at all, you'll know that my intention was to build an open-source toolchain targeting RISC-V (and intentionally not officially providing support for other platforms as the goal of RISCY BUSINESS is mainly to get people interested and excited about RISC-V). Furthermore, I do not want to contribute to "code-pollution" as Jon Blow calls it. As such, I've decided to give this project a very restrictive license. It is currently licensed as CC-BY-NC-ND-4.0 (tl;dr: look but don't touch). When RISCY BUSINESS resumes (caveat: no idea when that'll be), I will do a RISC-V implementation on the show which will be dual licensed as public domain or MIT. People will be free to fork that version to provide unofficial support for other platforms, but officially I am only going to support x86_64 in this Enterprise Business version and people may only use it (legally) if they pay me BIG BUCKS for an alternative license deal.
With that out of the way, let's talk about the technicals. Currently my thinking is that the lowest level layer of a Data System should only provide an execution environment and a built-in that allows you to define "primitives". A primitive is a node that has some native code associated with it that runs when a Transform is invoked on it. The idea is that there will be a specially privileged noid program packaged with the Data System which runs on start-up to bootstrap the rest of the system, which would involve building up the application, and possibly dropping privileges (such as being able to define primitives) for sandboxing purposes.
The simplest way I can think to spec that out is to simply say that you have a "Define primitive" built-in which takes an IMPLEMENTATION-DEFINED string. For example, if you are bootstrapping from a Forth, it could be a string of Forth words. In our case, I wanted to get maximal power with minimal implementation on an x86_64 Linux environment so this implementation uses a JIT that takes a string of hex characters. Those hex characters are just x86_64 machine code. In addition to that, you can specify an offset +- 255 from the current JITted code position with .[-]XX. syntax where XX is a hex pair. That offset will resolve to an absolute address and be inserted into the jitted code. We also have {symbol} syntax which attempts to runtime resolve the symbol with dlsym. Using this you could for example, write some machine code to call dlopen to load raylib and pop open a window for your application... etc. etc.
For the in-memory Representation, I took inspiration from *nix filesystems. Rather than building a tree/forest of Nodes, I've split the concept of a node into "dentry" and "inode". An "inode" provides a handle to your arbitrary data along with a field for type information so that you know what you're workin' with. "dentries," on the other hand, provide the tree structure. The obvious benefit of doing it this way is that you get the concept of "hard links" for free - you can have multiple locations in your tree (dentries) point to the same contents (inode). Most recently, I've added support for hidden nodes (think dotfiles on *nix filesystems) but rather than using the .-as-first-character-of-name hack, we have a proper flag for hidden nodes. Traversing the tree will skip hidden nodes unless you explicitly ask to traverse them. Using this idea, tagging nodes with arbitrary metadata has become as simple as creating a hidden "tags" node with your tags as children.
I used metadesk for my Storage representation. This project does not really get much benefit from Metadesk because I am using my own dentry/inode Representation, but it was a convenient way to type up my Noid nodes using the textual environments that exist today. I believe the future direction for storage is a binary format that is essentially like a tarball of files which act as logical buckets for inodes of various types as well as a file for the dentries. All files would be some standardised binary serialisation format (e.g. BSON) and within that you could compress data, e.g. a file holding inodes full of image data might want to use DEFLATE, but this would be done within the file rather than having all the various ways one might want to compress be standardised features of the storage format.
The future direction for Noid is to experiment with what primitives ought to be standardised as a base-language for bootstrapping higher level stuff.
During the jam, I was able to make it to (iirc) Noid Developer Preview 2 Service Pack 1 (tag v1.0.0-alpha.2.1 in the git repo). As of this writing, we are on Noid Developer Preview 3 Ninja Edition (v1.0.0-alpha.3) and additional nightly work is on branch master. You can view the changelog for the releases on the website.
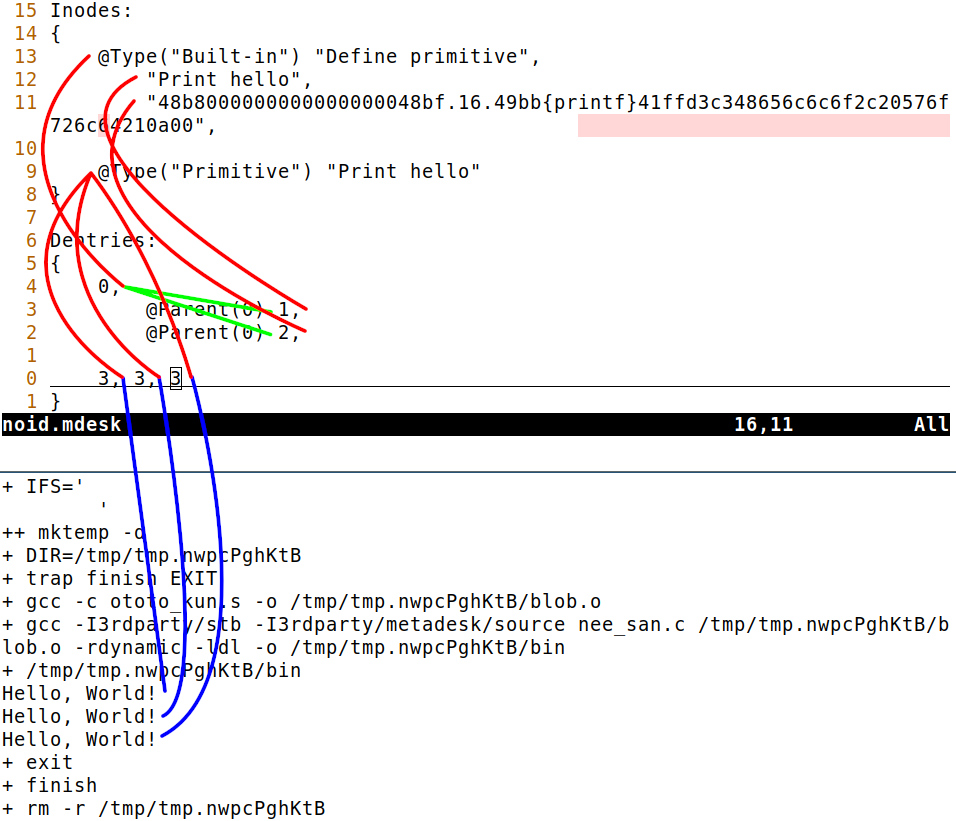
Currently the system demonstration is simply the bootstrap program defining a primitive that prints "Hello, World!\n" followed by calling it. I've shown this in the screenshot at the beginning of the post. The red lines show how dentries point to inodes, the green lines show how dentries point to each other (parent-child relationships), and the blue lines show how dentries that represent primitive calls result in output when the program is run!
Programming Languages and Data Systems
Mio Iwakura
June 8th, 2020
What is a Programming Language?
- A language is a system of communication
- Computer Programming communicates how data should be transformed
What does a Data System provide?
I call this concept of non-textual programming a "Data System." It is a DATA system rather than a PROGRAMMING system because it is a generic concept for a system that describes more than just a programming language. An image editor like GIMP is a data system; note that it has scripting capability but that is not the focus of the system. Same goes for advanced video editing software or anything else. A programming system is just a data system configured to produce executables rather than images, videos, or whatever else. A generic Data System can be configured to behave like any of these! A data SYSTEM is an entire systemic integrated toolchain for all aspects of working with data, of which transformation is just a small part. The exciting innovation to be had is not a new language to describe transformation, but rather all the other aspects of the tooling and their integration into a coherent system. That system consists of:
- Representation (e.g. ASG, RGB32F, LPCM24, etc.)
- Querying (e.g. grepping, diffing, etc.)
- Presentation (e.g. typeset, visualise, auralise, etc.)
- Editing (e.g. insertion, deletion, substitution, etc.)
- Storage (e.g. compress/decompress, read/write, etc.)
- Transformation (i.e. algorithms)
- Possibly other nice things! (e.g. version control)
The Problem
Conceptually, most programming has historically been done via a programming language with toolchain and ecosystem built around it. Thinking about it that way conflates these aspects with plain text:
- Representation: Plain Text
- Querying: Text-based tools (grep, diff)
- Presentation: Text (Usually monospace with syntax highlighting)
- Editing: Text Editor, possibly integrated with rest of toolchain in a GUI (IDE)
- Storage: Plain Text
- Transformation: Plain Text following Syntax & Semantics of Language
This is a fundamental mistake that has limited our tooling!
Counter Examples / Prior Work
- LISP ca. 1958 (Homoiconicity, Self-hosting, REPL)
- oN-Line System ca. 1968 (hypermedia, version control, cross-file editing, etc.)
- Bravo ca. 1974 (WYSIWYG documents)
- TeX ca. 1978 (Typesetting system)
- WEB ca. 1984 (Literate programming)
- Mathematica ca. 1988 (Notebook interface w/ interactive widgets)
- Color Forth ca. 1990s (Token editor, Compressed & pre-parsed source, Colour syntax)
The Solution
- Representation:
- homoiconic ASG (abstract semantic graph)
- arbitrary (meta)data linked with/alongside the ASG
- Querying: Filter by metadata tags, search results, procedures, types, etc.
- Presentation: can be enriched with metadata providing things like:
- Interactive multimedia widgets
- TeX expressions (linked up with the ASG)
- Hyperlinks
- Literate Programming
- Editing:
- Textual literate programming (markup input and/or WYSIWYG)
- Input widgets (e.g. colour picker)
- Node-based code editing (NB: powerful refactoring!)
- Storage:
- Once you have a transformation language and file IO, one can extend the system to support arbitrary file formats/compression schemes
- Compilation is just a series of transformation steps followed by write step in an executable format
- Transformation:
- The language component of a data system should ONLY focus on transformation.
- A data system should support extensibility via the transformation language to provide representation, querying, presentation, editing, and storage of arbitrary data formats
- Using that extensibility, one can write the data system in itself to achieve self-hosting
Loose Thoughts
- Important things:
- No undefined behaviour
- Minimal language, low-level (inline ASM, C-like feature set)
- Strong Type System
- Metaprogramming, hygienic macros
- Arbitrary Compile-time Code Execution
- Introspection
- Contracts, ability to restrict unsafe features, formal verification
- Easy bootstrapping from NOTHING, if I can't viably hand-weave the first stage into core rope memory your system is too complex.
That makes a lot more sense. I didn't get any of this from the previous submission because the actual info without context didn't meant anything to me.
Noid Developer Preview 4: Lean & Mean; Go Green!™️ OUT NOW!!!! Download your copy today @ https://noid.riscy.tv/
Alternatively, send us a FAX if you would like your copy as mail-order CD-ROM.
P.S. We are looking for feedback! If you have anything constructive to say about Noid, please comment it on this Computer Bulletin Board Service and we will put it in a Testimonials section on our Corporate WWW Page.
Edited by Neo Ar
on
Noid Developer Preview 5 CUSTOMER CARE PACK Halloween Pumpkin Patch™️ OUT NOW!!!! Download your copy today @ https://noid.riscy.tv/
Alternatively, send us a FAX if you would like your copy as mail-order CD-ROM.
P.S. We are looking for feedback! If you have anything constructive to say about Noid, please comment it on this Computer Bulletin Board Service and we will put it in a Testimonials section on our Corporate WWW Page.