my goal for the 2025 wheel reinvention jam was to explore what the assembly level debugging interface for the time travel debugger i'm working on could look like. the base tech currently allows me to record the execution of a program and replay it at instruction granularity. that is, i can seek to a particular instruction that executed and then single step the program state from there. and in fact, that's exactly what i did on day one: i just started with the first instruction in the recording, rendered its disassembly and the values of register writes, advanced the state to the next instruction, and so on:
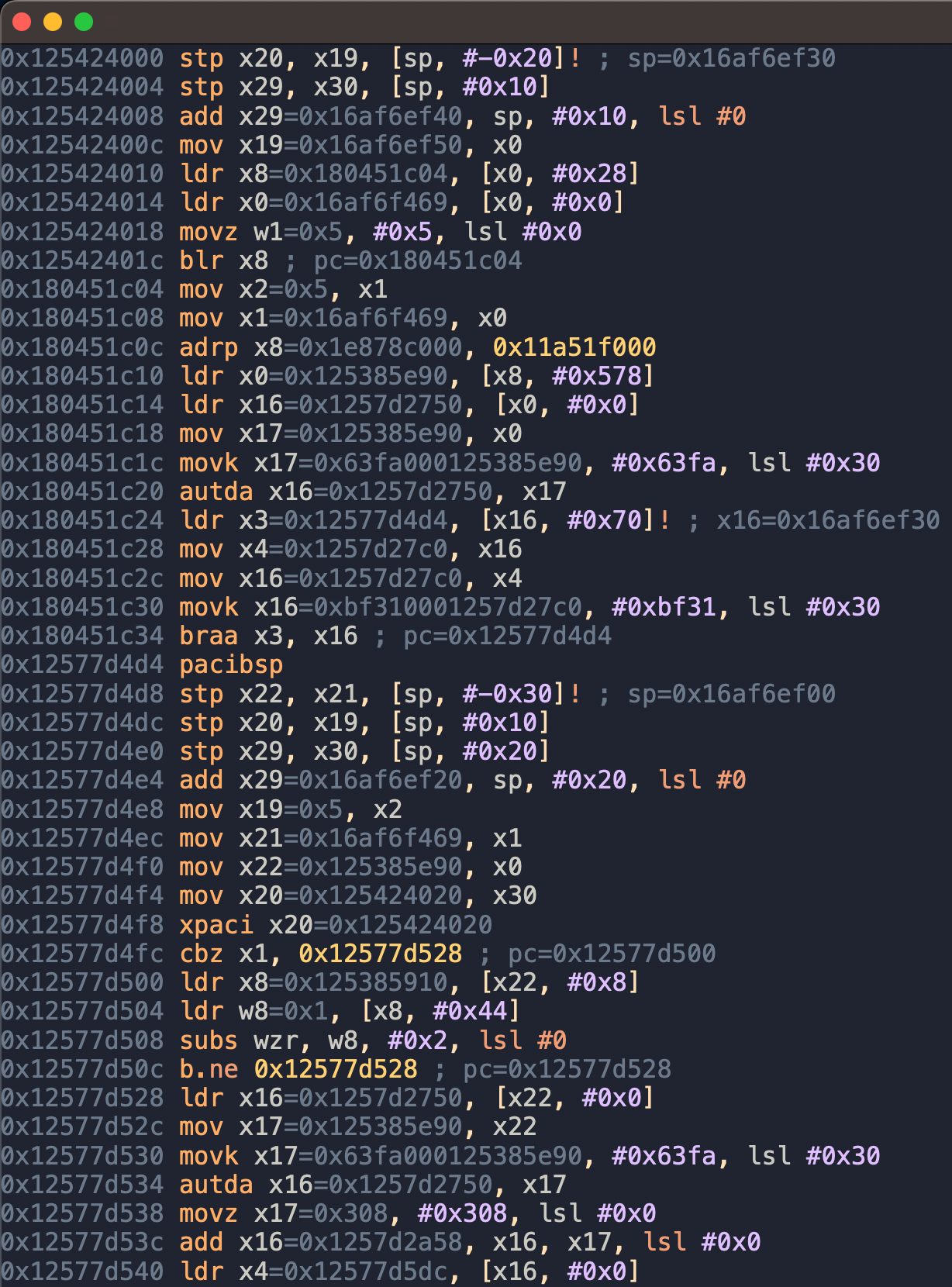
so far, not particularly insightful. of course, rendering symbol names instead of raw addresses would already have helped a lot, but i was interested in solving bigger issues.
if you've done assembly level debugging with regular step debuggers before, the above interface prob