
REDE is an IDE for Regular Expressions
So an Editor/Compiler/Debugger packaged together, though this will primarily be focusing on the 'Debugger' aspect
A quick pitch could be "debuggex with tweening"
Around the time the jam was announced, I didn't have a "weekend project" in mind, certainly not one which involved visualization.
Although, something I had on the backburner was adding regular expressions to my 4coder custom layer so somethin' somethin' 2 birds 1 stone
Because the jam duration is only 1 weekend, I'm not going to be able to write the whole thing from scratch, so I started working on the NFA construction, matching, and layout ahead of time and made a post to show where I was before the jam began.
So for the jam, I'll be working on visualizing how a Regex/NFA matches a string.
For some motivation/backstory, I learned about regex through Vim, but when I made the switch to 4coder I no longer had them available (and still currently don't ;-;)
When writing my own customizations, I briefly considered writing my own regex, and found Russ Cox's regex article which, while excellent, was lost on me at the time.
After revisiting it later, I could see why NFAs had a complexity of O(m*n) but it was this gist with only 2 lines of C code which got the big picture to click for me
I'll assume you're all at least vaguely familiar with regex so I won't be including a regex tutorial here.
Instead, I'll include some isolated NFAs to give a sense for how the regular operations map visually.

We can see that we always end in a final 'matching' state, and that literal character nodes are circles

Nodes which branch/split the path are square and their wires are teal
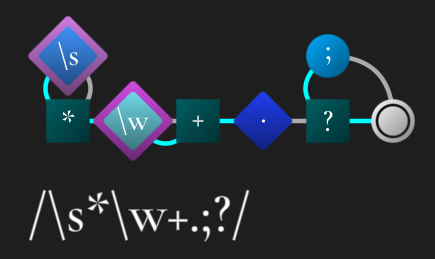
Character classes are diamonds, and the purple outlines represent which nodes are 'active'
So here's what the program looks like, but to get the full effect, with all the bells and whistles, you really have to see it in action :)
 rede_demo.mp4
rede_demo.mp4
Anyways, the main thing I wanted to demonstrate was how NFA's do a breadth-first search and only scan each character of the string once, so even if you haven't read the code, the O(m*n) complexity is clear. and why it's preferable to the exponential depth-first search Russ Cox decries in his article
"Well, surely it must be really difficult to get a spooky pathological regex for depth-first search", said the young developer
Well, as the folks at StackOverflow found out, it's not that hard at all
If you wanted to do something as rare and exotic as... trimming excess whitespace, you might write something like this:

Now, hopefully it's clear from the graph, that an NFA can search this with no issue.
"But, but... surely the NFA has pathological input as well", the young developer coped
I mean... only in the sense that most the time, the variable with upper bound m tends to be around 3 or 4
We could force it to be m for the entire length of the search with a pattern such as

But this regex is completely trivial and no sane-minded human thinks to type this unironically.
Even if they did, it still wouldn't really be an issue in terms of either time or space complexity.
You typed 32 characters, we allocated 32 nodes :)