gingerBill
First off, how do you encode an zero rotation, half a turn or a full turn around a particular axis? At these particular rotations (depending on the particular encoding), it removes all the information about its axis. With quaternions, all angles of rotation are unique and still keep all the information unlike RPs where the same rotation can be represented in multiple ways.
zero rotation is 0,0,0,1 and full 360 rotation is 0,0,0,-1. There is no axis information here at all.
The 180° turn has w = 0 and the x, y and z matching the unit rotation axis.
Which is kind of my point. RPs cannot be used to store an orientation which can then be used as a rotation. Depending on the encoding, either half a turn or a full turn cannot be represented with RPs.
Edited by Ginger Bill
on
gingerBill
You lose information when you reduce the degrees of freedom.
Yes, and for Gibbs vectors this information is length of a vector. Because we already know their length, it equals to one, these are versors. So we lose 4th dimension to drop length information we already know.
gingerBill
Show me the evidence that the memory saving cost is worth it over the performance one in the real world and not the theoretical one.
Real world fact #1: 3 is less than 4.
Gibbs vectors are smaller than quaternions.
Real world fact #2: The fallacy of your statement is that it assumes Gibbs vectors require more compute power than quaternions. They don't.
Quaternion product:
1 2 3 4 | a.x * b.w + b.x * a.w + (a.y * b.z - b.y * a.z) a.y * b.w + b.y * a.w + (a.z * b.x - b.z * a.x) a.z * b.w + b.z * a.w + (a.x * b.y - b.x * a.y) a.w * b.w - (a.x * b.x + a.y * b.y + a.z * b.z) |
Gibbs vector product:
Removing forth vector component by replacing it with 1, adding 3 divides to encode dot product into the vector components:
1 2 3 4 | d = 1 * 1 - (a.x * b.x + a.y * b.y + a.z * b.z) a.x * 1 + b.x * 1 + (a.y * b.z - b.y * a.z) / d a.y * 1 + b.y * 1 + (a.z * b.x - b.z * a.x) / d a.z * 1 + b.z * 1 + (a.x * b.y - b.x * a.y) / d |
Removing 7 multiply instructions because we know multiplying a value by 1 yields that value without a change:
1 2 3 4 | d = 1 - (a.x * b.x + a.y * b.y + a.z * b.z) a.x + b.x + (a.y * b.z - b.y * a.z) / w a.y + b.y + (a.z * b.x - b.z * a.x) / w a.z + b.z + (a.x * b.y - b.x * a.y) / w |
7 fp multiplies less, 3 fp divides more than quaternions.
gingerBill
Show me the evidence that the memory saving cost is worth it over the performance one in the real world and not the theoretical one.
It's a win in space / win in performance situation, that's the reality.
3 divides may be more expensive than 7 multiplies. Show me the empirical evidence, not theoretical! I don't care if 3 is less than 4 if the real world cost doesn't actually work.
You have lost information and you have lost over advantages that quaternions possess. You cannot represent all angles and you cannot interpolate.
You have lost information and you have lost over advantages that quaternions possess. You cannot represent all angles and you cannot interpolate.
ratchetfreak
For example take a car on a flat surface turning in a circle.
At some point it needs to be rotated 180° compared to the starting position. At that point your car will glitch out and depending on how you created the turning transform (iteratively or closed function) will add inaccuracies for the future. So it may recover or it will remain with a glitched transform until it gets reset.
turning in a circle
needs to be rotated 180° compared to the starting position
How's turning in a circle related to immediately turning 180°?
gingerBill
3 divides may be more expensive than 7 multiplies
Excuse me?
gingerBill
You have lost information
Length of a vector, not lost but assumed to be one.
gingerBill
and you have lost over advantages that quaternions possess
I lost exactly 1 advantage, rotating 180° in one operation no one does practically.
gingerBill
You cannot represent all angles
That's a lie, they can represent any angle you want, otherwise how's GpuLib example (linked in the first post) rotates camera full 360° with Gibbs vectors? Are you sure you applied them practically in real world applications?
What I should have said is "you cannot represent all angles uniquely".
"3 divides may be more expensive than 7 multiplies" It is on many architectures. Show me the empirical evidence!
"3 divides may be more expensive than 7 multiplies" It is on many architectures. Show me the empirical evidence!
gingerBill
"3 divides may be more expensive than 7 multiplies" It is on many architectures. Show me the empirical evidence!
I like the transition between unsure "may be" to confident "it is" :) Is it because you checked the cost yourself and got so confident in saying this? Which architecture we're talking about?
ProceduralgingerBill
"3 divides may be more expensive than 7 multiplies" It is on many architectures. Show me the empirical evidence!
I like the transition between unsure "may be" to confident "it is" :) Is it because you checked the cost yourself and got so confident in saying this? Which architecture we're talking about?
Show me the empirical evidence to prove your points! As much I love doing theoretical work, it means diddly squat if it doesn't prove itself in the real world.
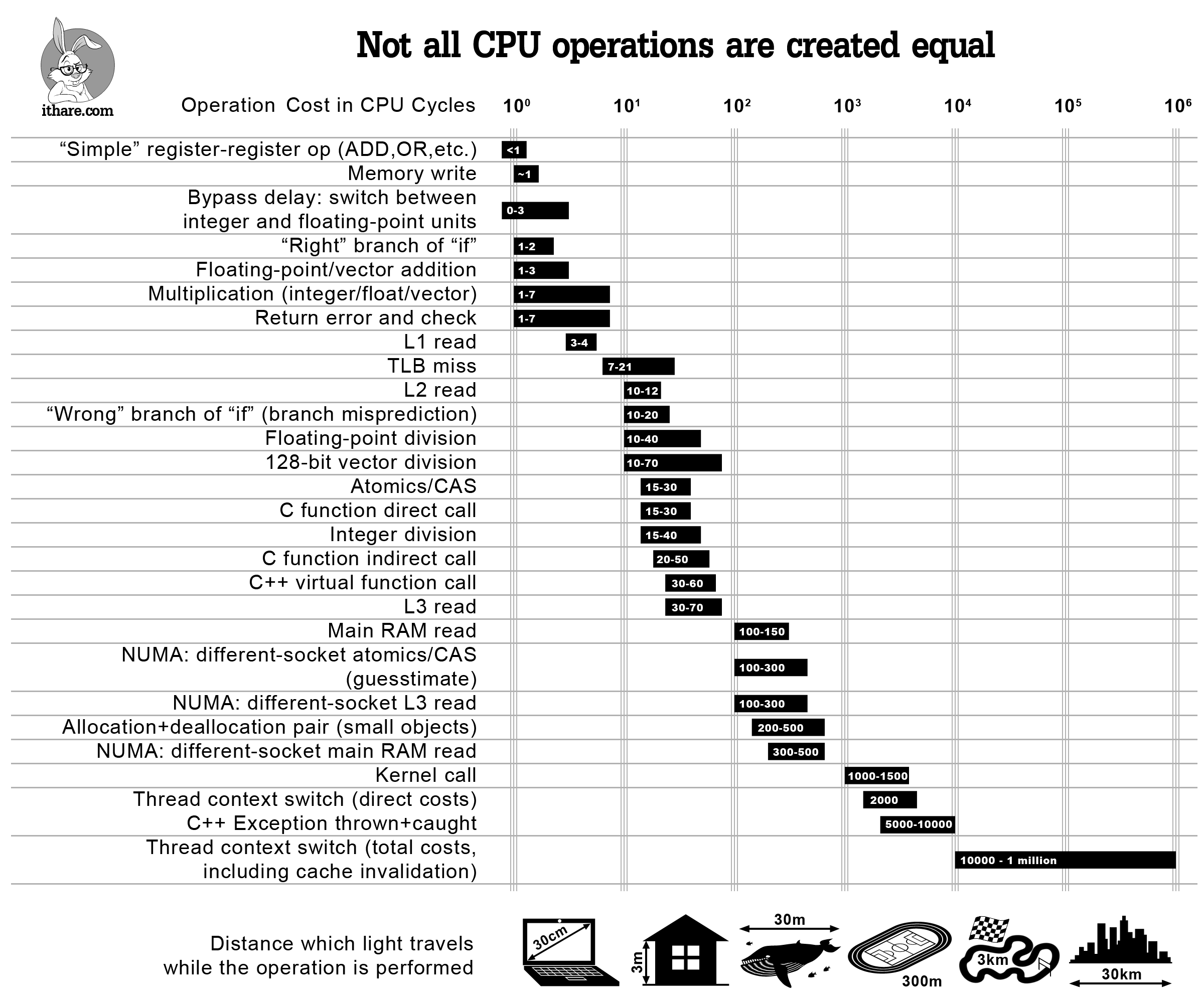
Before talking about the performance cost I want to get back to this statement of yours:
Should I start teach you how computer memory work? That 96 bits is less than 128 and when multiplied to great amounts, say, to 100_000_000 of such vectors, you save 400 megabytes of data transfer? Or that moving data has more cost in modern architectures than ALU operations? That you can fit more stuff in cache?
gingerBill
I don't care if 3 is less than 4 if the real world cost doesn't actually work.
Should I start teach you how computer memory work? That 96 bits is less than 128 and when multiplied to great amounts, say, to 100_000_000 of such vectors, you save 400 megabytes of data transfer? Or that moving data has more cost in modern architectures than ALU operations? That you can fit more stuff in cache?
I'm not going to continue this thread until you show me the empirical evidence to prove your points!
Last remark, most GPUs require 16 byte alignment for both vec3 and vec4.
Last remark, most GPUs require 16 byte alignment for both vec3 and vec4.
Proceduralratchetfreak
For example take a car on a flat surface turning in a circle.
At some point it needs to be rotated 180° compared to the starting position. At that point your car will glitch out and depending on how you created the turning transform (iteratively or closed function) will add inaccuracies for the future. So it may recover or it will remain with a glitched transform until it gets reset.
turning in a circle
needs to be rotated 180° compared to the starting position
How's turning in a circle related to immediately turning 180°?
orienting a model is usually done by composing orientations which are stored separately and updated individually, if any of those orientations being composed is a 180° rotation you get a glitch.
If the car model faces north by default and it should be displayed facing south the model to world rotation is a 180° rotation
Procedural
I like the transition between unsure "may be" to confident "it is" :) Is it because you checked the cost yourself and got so confident in saying this? Which architecture we're talking about?
I like the transition between unsure "may be" to confident "it is" :) Is it because you checked the cost yourself and got so confident in saying this? Which architecture we're talking about?
Yes, it is. DIV is more expensive than MUL. You should be actually doing 1.0/t and then multiplying this three times to xyz.
From http://www.agner.org/optimize/instruction_tables.pdf on skylake:
MULSS - Latency=4, Throughput=0.5
DIVSS - Latency=11, Throughput=3
Similar thing happens also on GPU.
On ARM it will be even worse.
gingerBill
Last remark, most GPUs require 16 byte alignment for both vec3 and vec4.
Afaik there are limitations like that only for uniforms in some cases. But in vertex buffer or textures there is no such requirement.
Edited by Mārtiņš Možeiko
on
I think it'll be fair to compare 1 div to 2 muls (given 3 divs of Gibbs vector vs 7 muls of quaternion), also we should compare vector instruction costs...
For Skylake the performance of MULPS and DIVPS is the same as for MULSS and DIVSS.
Edited by Mārtiņš Možeiko
on